# load packages
library(tidyverse)
library(countdown)
library(scales)
library(ggthemes)
library(glue)
# set theme for ggplot2
ggplot2::theme_set(ggplot2::theme_minimal(base_size = 14))
# set width of code output
options(width = 65)
# set figure parameters for knitr
knitr::opts_chunk$set(
fig.width = 7, # 7" width
fig.asp = 0.618, # the golden ratio
fig.retina = 3, # dpi multiplier for displaying HTML output on retina
fig.align = "center", # center align figures
dpi = 300 # higher dpi, sharper image
)Data wrangling + tidying - I
Lecture 3
Today’s focus
Dive into data wrangling and tidying (for better/easier visualization) within a single data frame
Peek at one more layer: statistics
So far we’ve reviewed data, aesthetics, geometries
We’ll soon review facets and themes
In your HW you’ll revisit coordinates

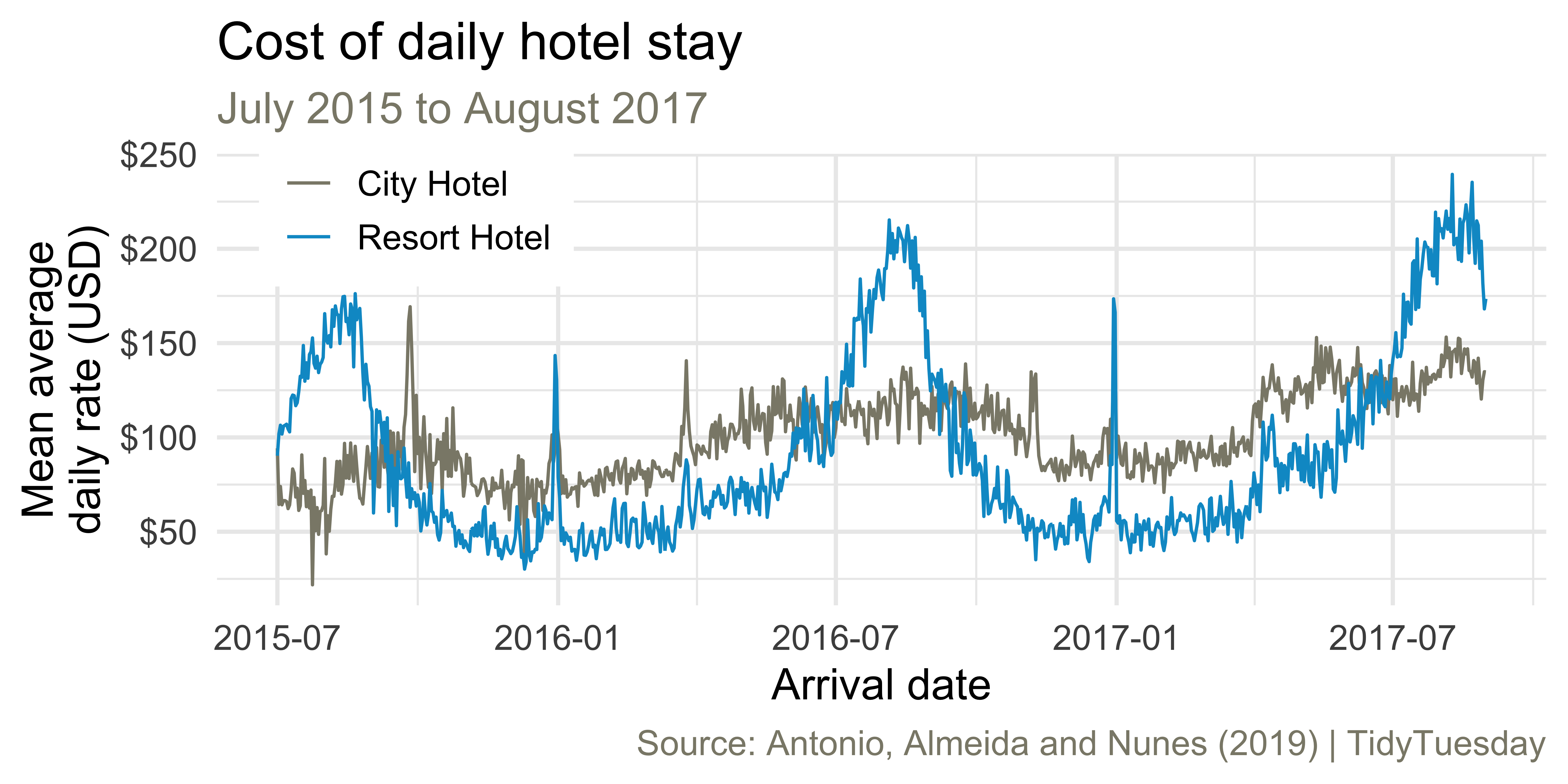
Average cost of daily stay
ae-03 - Part 1: Let’s recreate this visualization!
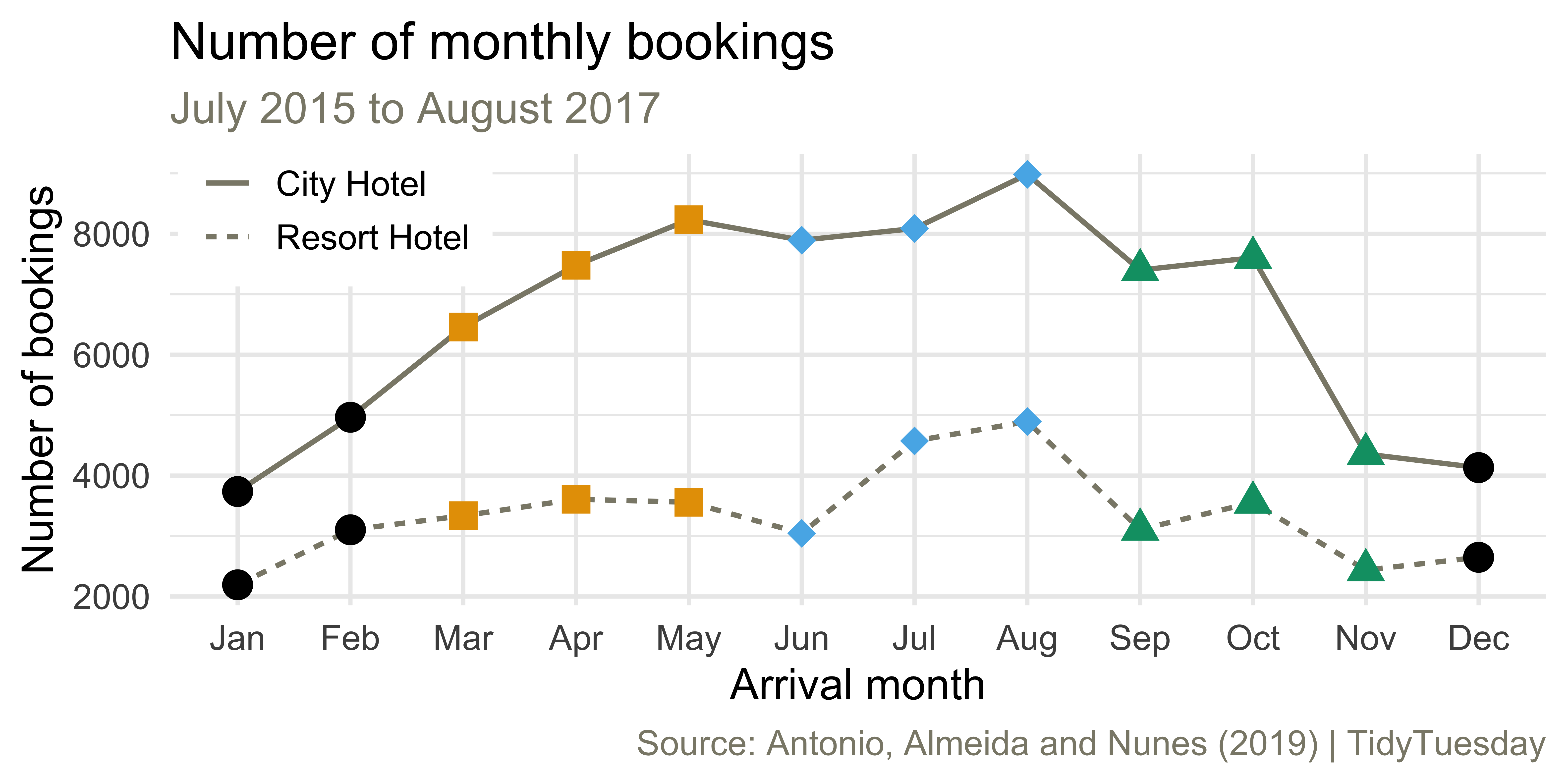
Monthly bookings
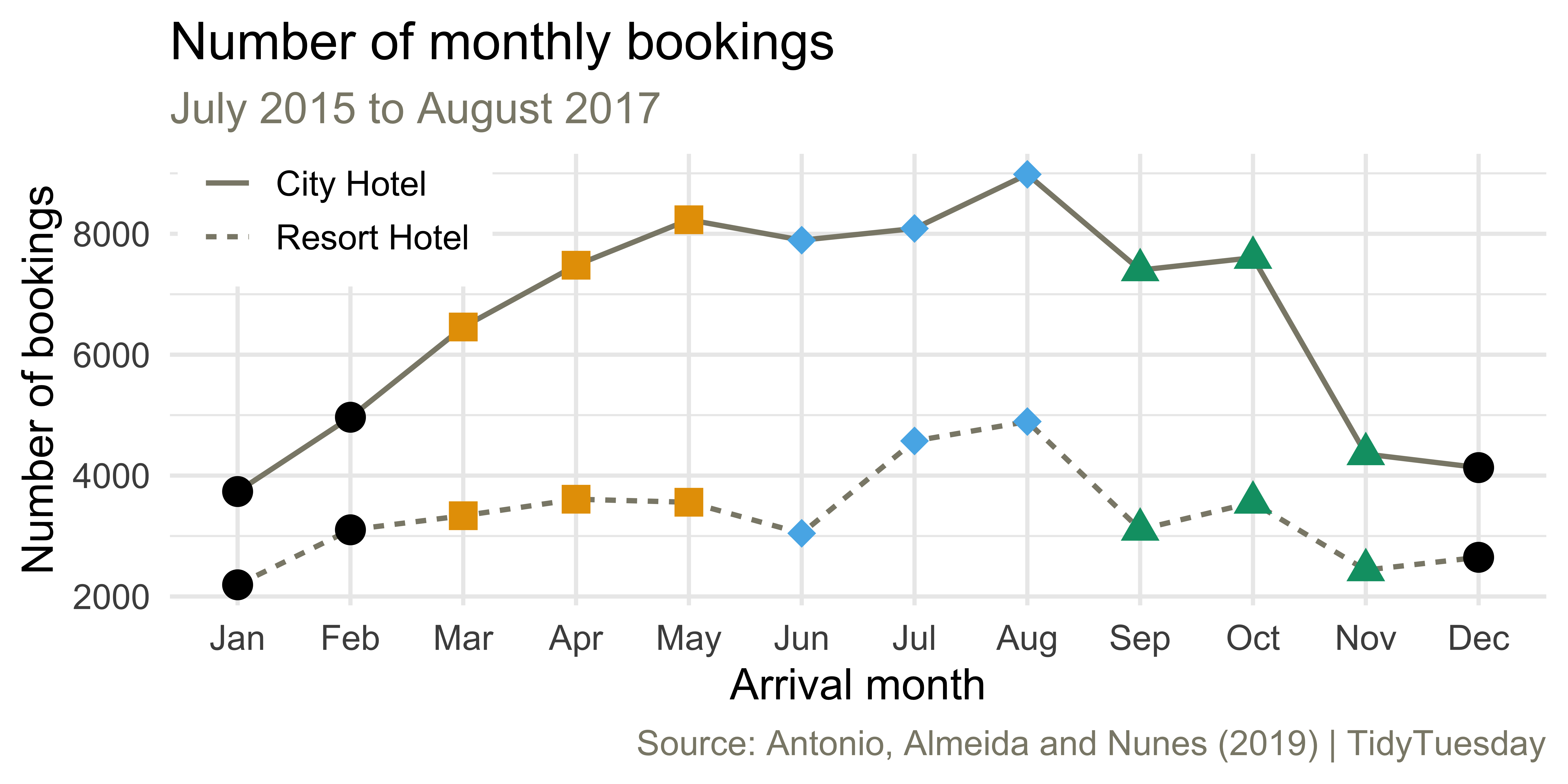
Monthly bookings
ae-03 - Part 2: Let’s recreate this visualization!
Livecoding
Reveal below for code developed during live coding session.
Code
hotels <- hotels |>
mutate(
arrival_date_month = fct_relevel(arrival_date_month, month.name),
season = case_when(
arrival_date_month %in% c("December", "January", "February") ~ "Winter",
arrival_date_month %in% c("March", "April", "May") ~ "Spring",
arrival_date_month %in% c("June", "July", "August") ~ "Summer",
TRUE ~ "Fall"
),
season = fct_relevel(season, "Winter", "Spring", "Summer", "Fall")
)
hotels |>
count(season, hotel, arrival_date_month) |>
ggplot(aes(x = arrival_date_month, y = n, group = hotel, linetype = hotel)) +
geom_line(linewidth = 0.8, color = "cornsilk4") +
geom_point(aes(shape = season, color = season), size = 4, show.legend = FALSE) +
scale_x_discrete(labels = month.abb) +
scale_color_colorblind() +
scale_shape_manual(values = c("circle", "square", "diamond", "triangle")) +
labs(
x = "Arrival month", y = "Number of bookings", linetype = NULL,
title = "Number of monthly bookings",
subtitle = "July 2015 to August 2017",
caption = "Source: Antonio, Almeida and Nunes (2019) | TidyTuesday"
) +
coord_cartesian(clip = "off") +
theme(
legend.position = c(0.12, 0.9),
legend.box.background = element_rect(fill = "white", color = "white"),
plot.subtitle = element_text(color = "cornsilk4"),
plot.caption = element_text(color = "cornsilk4")
)![]()